Big Data Step by Step.Part 4: Experiments with HBase
Parts in this series:
Big Data Step by Step. Part 1: Getting Started
Big Data Step by Step. Part 2: Setting up the Cluster
Big Data Step by Step. Part 3: Experiments with MapReduce
Big Data Step by Step. Part 4: Experiments with HBase
HBase
HBase is the column store database of the Hadoop family. As mentioned previously, MapReduce is sequential in nature and will not allow random access. This means that finding something specific in a big data file will introduce enormous latency, which is the time to read and process the entire file. While this may be fine for batch jobs that run overnight, it is not acceptable in situations where instant access is desired. HBase uses HDFS to store large amounts of data, but makes it randomly accessible by storing data as columns of Key-Value pairs. It makes it possible to store and search very sparse data sets (data sets with large “gaps”) in an efficient way. HBase is not a database in the classic sense. It does not provide full ACID (Atomicity, Consistency, Isolation, Durability) in the way a relational database does. More on this subject can be found here. The main purpose of HBase is the ability to have fast random access to massive data sets.
HBase can be accessed from Java code. This article will demonstrate some examples.
HBase installation
In the second article of this series we installed a Cloudera cluster, but we did not include HBase yet. Fortunately, installation is quite easy with the Cloudera Manager web interface. Log in to http://cloudera-000.bigdata.local:7180 and click on Clusters -> Cluster 1:

In the Actions menu, click to add a service:

Choose to add HBase:

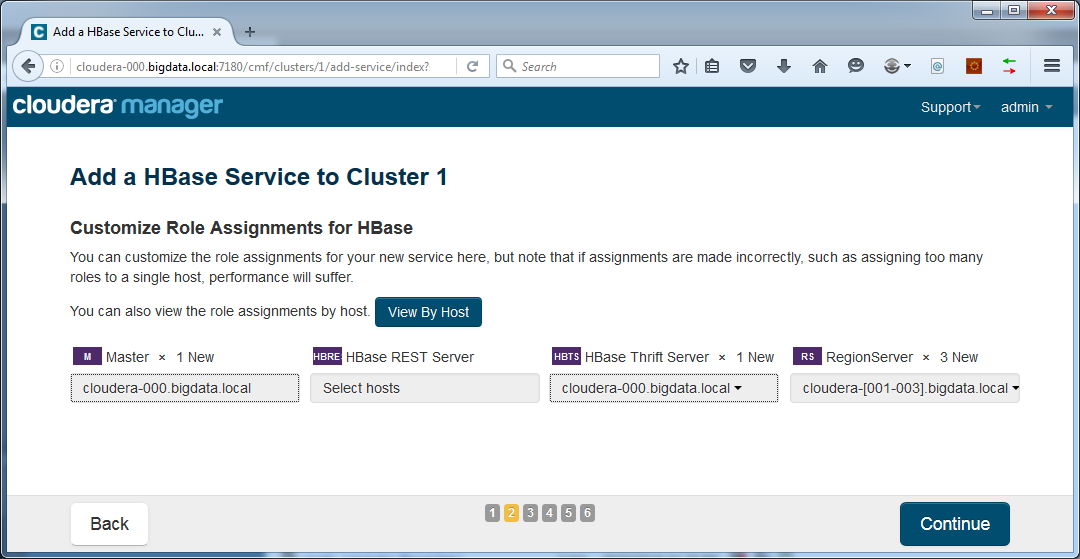
Assign roles to hosts. In this case we keep the defaults, assigning the Master server to our master node and the RegionServers to our worker nodes. Add an HBase Thrift Server to the master machine:
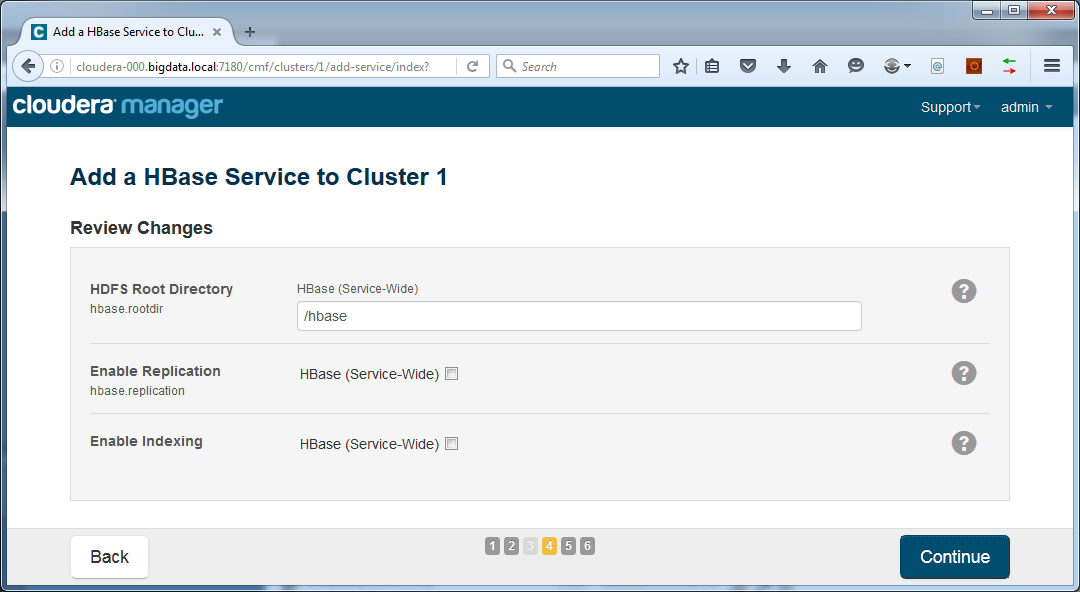
Leave default settings:
Let Cloudera Manager install HBase:

Finish:

In the cluster overview, the following icon will now show, indicating that some configurations need to be redeployed:

Click on it the icon and let redeployment finish.
In order to make HBase visible in Hue, go to Hue configuration and make sure that the HBase Service is set to HBase:

Do the same for the HBase Thrift Server:

If necessary, save changes and restart Hue from the Cluster overview page to deploy configuration settings.
Open Hue and verify that the HBase Data Browser is available:

Your HBase installation is now ready!
HBase Schema Design
Before we can put data into HBase, we need a schema. Some basic guidelines apply to HBase schema design. First thing to do when designing an HBase schema is to define the most likely queries for it to serve. Then the schema can be designed around these queries. This requires some background on the inner workings of HBase. A very interesting introduction can be found here.
Data is split and divided over machines by key, which means that keys that are close together are likely to end up in the same machine of your cluster. This is a problem for monotonously increasing keys, like the timestamps of a log file. Using timestamps as keys could create the situation where a sequential read will concentrate all activity in one place (a “hotspot”), defying the purpose of distributed computing. The same applies to writing log data in high velocity. Since timestamps will not differ much from one log line to the next, almost all write activity will take place on the same node, gradually moving to the next node as time progresses but never distributing load over all nodes simultaneously. A possible workaround is hashing the key, which makes sequential keys end up in wildly different places in the cluster. This way, reading or writing rows with similar keys will be distributed over all the nodes, reaping the benefit of combined throughput of all nodes.
Due to its structure, the most beneficial use of HBase is access to data identified by a single key. This includes things like retrieving all items of a given user on social media (like Pinterest does), where the username is used as key. For this scenario HBase can be lightning fast, almost regardless of table size.
HBase becomes more problematic when query selection criteria become more complex. A (pseudo SQL) query like “SELECT something FROM some_table WHERE some_non_key_column = some_value” will result in a full table scan, since HBase does not allow secondary indexing. It has no way of locating items of which the non-key column has a certain value, so it must read everything to find matching items. Only the row keys are randomly accessible. In this case we are almost back to square one with a high-latency “read-everything” solution.
With this information in mind, we might conclude that HBase is not the right solution for our problem. We need a database for fast random selection based on all kinds of columns, including the non-key ones. A possible workaround is to create additional tables where the non-key columns are used as keys, effectively replicating data as a replacement for secondary indexes. Although usable, the redundancy it introduces is not very desirable and is better avoided.
Enter Apache Phoenix. This component extends HBase to allow SQL querying. It also provides secondary indexing to solve the non-key column selection problem. Furthermore it provides a JDBC driver, enabling access from almost any reporting tool. Using the combination of HBase and Phoenix we can report nicely on virtually unlimited volumes of log data with minimal latency. Query execution time will be proportional to resultset size, instead of table size. In the next article we will learn more about this tool. For now we continue writing code to move our firewall log data into HBase.
The job
First we need to create the schema for our database. We will do this from Hue, although it can also be done from Java code.
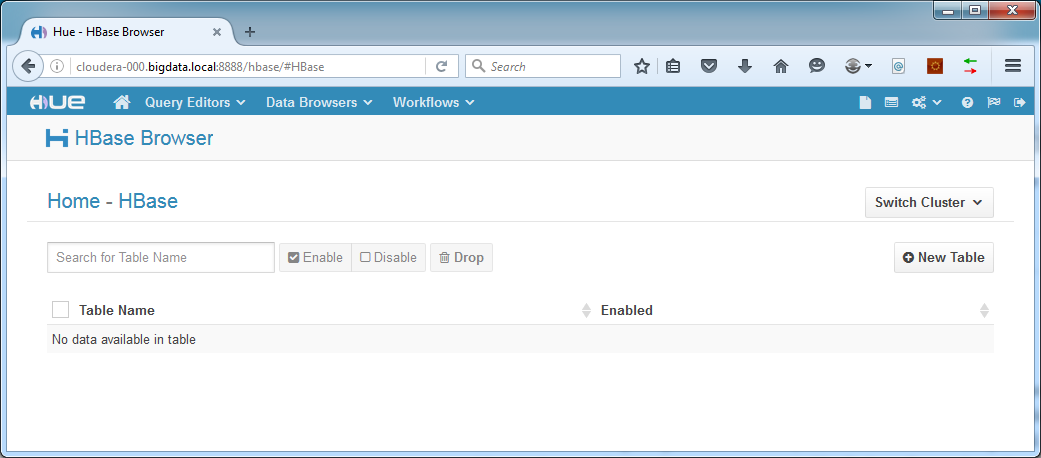
Open the HBase Data Browser in Hue:
Click the “New Table” button:
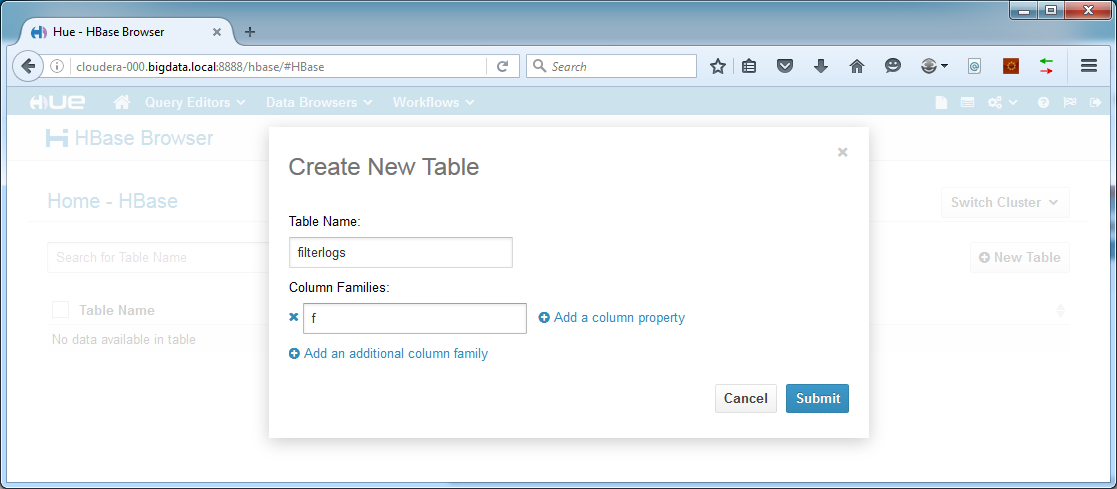
Call the table “filterlogs” and create a column family called “f”. Since the full name is included in every record, using a very short family name is beneficial to both disk usage and performance. Click Submit.
For moving our log data into HBase we will be using Java. The code is as follows:
[code language=”java”]
package com.arthurvogels.bigdatablog.filterlogtohbase;
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
/**
* @author ArthurVogels
*/
public class FilterLogToHBaseMain {
private static String LOGFILEPATH = "d:/01filterlog.log";
private static String HBASEHOST = "cloudera-000.bigdata.local";
private static String TABLENAME = "filterlogs";
/**
*
* @param args
*/
public static void main(String[] args) {
try {
// Open logfile
FileReader fr = new FileReader(LOGFILEPATH);
BufferedReader br = new BufferedReader(fr);
String logLine;
List puts = new ArrayList();
// Connect to HBase
Configuration hbConfig = HBaseConfiguration.create();
hbConfig.set("hbase.zookeeper.quorum", HBASEHOST);
Connection conn = ConnectionFactory.createConnection(hbConfig);
// Loop all lines in logfile
while((logLine = br.readLine()) != null){
// Calculate hash as row key to evenly spread records over HBase Regions
byte[] rowKey = Bytes.toBytes(DigestUtils.shaHex(logLine + Math.random()));
// Convert log line to Put and add to list
puts.add(logLineToPut(logLine, rowKey));
// If list contains 10000 items, put all to HBase
if(puts.size()>100000){
System.out.println("Flushing to HBase…");
// Put to HBase filterlogs table
conn.getTable(TableName.valueOf(TABLENAME)).put(puts);
// Reset list
puts = new ArrayList();
}
}
// Put the last items to HBase filterlogs table
conn.getTable(TableName.valueOf(TABLENAME)).put(puts);
// Close reader and HBase connection
br.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* Dissects the log line into column name and value pairs and puts those into an HBase Put object
*
* @param logLine A string containing the log line
* @return An HBase Put object containing column name and value pairs
* @throws Exception
*/
private static Put logLineToPut(String logLine, byte[] rowKey) throws Exception {
String ipVersion = "";
String protocolId = "-1";
int currentColumn = 0;
// Create new Put
Put put = new Put(rowKey);
// Chop the line into three parts: the timestamp, the hostname, the logname and the logdata
StringTokenizer st = new StringTokenizer(logLine, " ");
// First do the columns that are always present
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("timestamp"), Bytes.toBytes(st.nextToken())); // Timestamp
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("hostname"), Bytes.toBytes(st.nextToken())); // Hostname
String logName = st.nextToken(); // Logname
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("logname"), Bytes.toBytes(logName.substring(0, logName.length() – 1))); // Logname
// The next token is the actual logdata string
String logData = st.nextToken();
// Split the logdata by comma delimiter
String[] tokens = logData.split(",", -1);
// Set what column we are in the logline:
currentColumn = 0;
// The following fields are always present
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("rule_number"), Bytes.toBytes(tokens[currentColumn])); // Rule number
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("sub_rule_number"), Bytes.toBytes(tokens[++currentColumn])); // Sub rule number
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("anchor"), Bytes.toBytes(tokens[++currentColumn])); // Anchor
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tracker"), Bytes.toBytes(tokens[++currentColumn])); // Tracker
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("real_interface"), Bytes.toBytes(tokens[++currentColumn])); // Real interface
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("reason"), Bytes.toBytes(tokens[++currentColumn])); // Reason
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("action"), Bytes.toBytes(tokens[++currentColumn])); // Action
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("direction"), Bytes.toBytes(tokens[++currentColumn])); // Direction
// Get the IP version
ipVersion = tokens[++currentColumn];
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ip_version"), Bytes.toBytes(ipVersion)); // IP Version
// In case of IPv4
if (ipVersion.equals("4")) {
// Put everything that is universal for IPv4 loglines
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv4_tos"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 TOS
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv4_ecn"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 ECN
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv4_ttl"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 TTL
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv4_id"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 ID
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv4_offset"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 Offset
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv4_flags"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 Flags
protocolId = tokens[++currentColumn]; // IPv4 protocol ID
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv4_protocol_id"), Bytes.toBytes(protocolId)); // IPv4 Protocol ID
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv4_protocol_text"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 Protocol Text
}
// In case of IPv6
if (ipVersion.equals("6")) {
// Put everything that is universal for IPv6 loglines
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_class"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Class
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_flow_label"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Flow Label
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_hop_limit"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Hop Limit
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_protocol_text"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Protocol Text
protocolId = tokens[++currentColumn]; // IPv6 protocol ID
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_protocol_id"), Bytes.toBytes(protocolId)); // IPv6 protocol ID
}
// Some generic IP columns
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ip_packet_length"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Class
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ip_source_address"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Flow Label
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ip_destination_address"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Hop Limit
// In case of TCP
if (protocolId.equals("6")) {
// Put everything that is universal for TCP loglines
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tcp_source_port"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 TOS
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tcp_destination_port"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 ECN
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tcp_data_length"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 TTL
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tcp_flags"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 ID
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tcp_sequence_number"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 Offset
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tcp_ack_number"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 Flags
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tcp_window"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 TOS
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tcp_urg"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 ECN
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("tcp_options"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 TTL
}
// In case of UDP
if (protocolId.equals("17")) {
// Put everything that is universal for UDP loglines
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("udp_source_port"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 TOS
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("udp_destination_port"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 ECN
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("udp_data_length"), Bytes.toBytes(tokens[++currentColumn])); // IPv4 TTL
}
// In case of ICMP
if (protocolId.equals("1")) {
// In case of ICMP v4
if(ipVersion.equals("4")){
// Put everything that is universal for ICMPv4 loglines
// ICMPv4 Type
String icmpType = tokens[++currentColumn];
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_type"), Bytes.toBytes(icmpType)); // ICMPv4 Type
boolean knownTypeFound = false;
// If type is icmp echo data
if(icmpType.equals("request") || icmpType.equals("reply")){
// Put everything that is universal for ICMP echo data
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_id"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 ID
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_sequence_number"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Sequence Number
knownTypeFound = true;
}
// If type is icmp unreachproto
if(icmpType.equals("unreachproto")){
// Put everything that is universal for ICMP unreachproto
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_destination_ip"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Destination IP
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_unreachable_protocol_id"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Unreachable Protocol ID
knownTypeFound = true;
}
// If type is icmp unreachport
if(icmpType.equals("unreachport")){
// Put everything that is universal for ICMP unreachport
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_destination_ip"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Destination IP
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_unreachable_protocol_id"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Unreachable Protocol ID
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_unreachable_port_number"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Unreachable Port Number
knownTypeFound = true;
}
// If type is icmp other unreachable
if(icmpType.equals("unreach") || icmpType.equals("timexceed") || icmpType.equals("paramprob") || icmpType.equals("redirect") || icmpType.equals("maskreply")){
// Put everything that is universal for ICMP other unreachable
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_description"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Description
knownTypeFound = true;
}
// If type is icmp needfrag
if(icmpType.equals("needfrag")){
// Put everything that is universal for ICMP needfrag
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_destination_ip"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Destination IP
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_mtu"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 MTU
knownTypeFound = true;
}
// If type is icmp tstamp
if(icmpType.equals("tstamp")){
// Put everything that is universal for ICMP needfrag
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_id"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 ID
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_sequence_number"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Sequence Number
knownTypeFound = true;
}
// If type is icmp tstampreply
if(icmpType.equals("tstampreply")){
// Put everything that is universal for TCP loglines
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_id"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 ID
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_sequence_number"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Sequence Number
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_originate_timestamp"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Originate Timestamp
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_receive_timestamp"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Receive Timestamp
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_transmit_timestamp"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Transmit Timestamp
knownTypeFound = true;
}
// If no known type was found then it must be a description
if(!knownTypeFound){
// Put description
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmp_description"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv4 Description
}
}
else{
// Logging gives erroneous records.
protocolId = "-1";
}
}
// In case of ICMPv6
if (protocolId.equals("58")) {
// Put everything that is universal for ICMPv6 loglines
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("icmpv6_description"), Bytes.toBytes(tokens[++currentColumn])); // ICMPv6 Description
}
// In case of IGMP
if (protocolId.equals("2")) {
// Put everything that is universal for IGMP loglines
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("igmp_description"), Bytes.toBytes(tokens[++currentColumn])); // IGMP Description
}
// In case of IPv6 Hop-by-Hop options
if (protocolId.equals("0")) {
// Put everything that is universal for IPv6 Hop-by-Hop options
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_hop_by_hop_opts_1"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Hop-byHop Opts 1
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_hop_by_hop_opts_2"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Hop-byHop Opts 2
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_hop_by_hop_opts_3"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Hop-byHop Opts 3
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_hop_by_hop_opts_4"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Hop-byHop Opts 4
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("ipv6_hop_by_hop_opts_5"), Bytes.toBytes(tokens[++currentColumn])); // IPv6 Hop-byHop Opts 5
}
// If this is a line of a known protocol
if(!protocolId.equals("-1")){
// Finished
// Return the Put
return put;
} else{ // Unknown or not implemented protocol
// Add a column to indicate the unprocessable line
put.addImmutable(Bytes.toBytes("f"), Bytes.toBytes("unprocessable_line"), Bytes.toBytes(logLine));
// Return the Put
return put;
}
}
}
[/code]
The code reads logfiles line by line and splits them into columns, based on the pfSense filterlog grammar. It then writes the column values to HBase.
We can browse our HBase table from Hue in the Data Browser:

At this moment it still needs to read the full table to find non-indexed items, making it almost as “slow” as MapReduce. However, we already enjoy the advantage of flexible querying, without the need for rewriting massive amounts of Java code in a MapReduce program for every new report.
Final thoughts
In this article we explored HBase as a datastore for our log files. We installed the product, moved log data into it and showed the the table in Hue.
Next time we will make secondary indexing and SQL queries possible. We will turn our HBase installation into a fully functional log reporting system with Apache Phoenix.
Stay tuned!
Neem contact met op met Carl voor meer informatie over Big Data

Neem contact op met Ebicus via het contactformulier of raadpleeg direct één van onze collega’s om je direct te ondersteunen!